如何在sparkStreaming中保存状态
1、从kafka里面取数据到sparkStreaming里面,然后再把数据保存到数据中关键点,不是每个数据都需要创建连接,只需要为每个分区创建一个连接就可以了
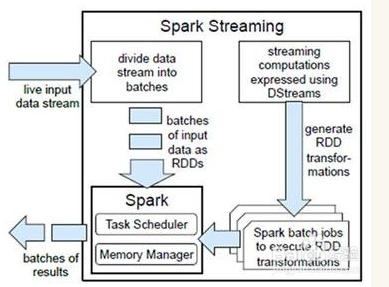
2、下面是一个简单的例子import java.sql.{ Connection, DriverManager } import com.oracle._ import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka._ import org.apache.spark.{ SparkConf, SparkContext } /** *
3、从kafka上面读取数据,然后保存到数据库上面,虽然一般不建议把数据保存到数据库中,(保存到数据库中的时候可以建立连接池) * 如果是保存到hbase上面也可以使用这样的方法
4、为每个分区创建一个RDD连接,而不是为每个数据建立一个连接 */ object StreamToOracle { def main(args: Array[String]) { val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]") val sc = new SparkContext(sparkConf) val ssc = new StreamingContext(sc, Seconds(10)) //ssc.checkpoint("checkpoint") val topic = "test" val topicMap = topic.split(",").map((_, 1)).toMap val lines = KafkaUtils.createStream(ssc, "192.168.10.209:2181,192.168.10.219:2181,192.168.10.199:2181", "ssk", topicMap).map(_._2) //

5、每个RDD进行操作 lines.foreachRDD(rdd => { rdd.foreachPartition(part足毂忍珩itionOfRecords => { //重点在这里,在每一个分区里面建立一个连接 val connection = getConnection() partitionOfRecords.foreach(line => { val info = line.split(":") val ip = info(0) val mesType = info(1) val data = info(2) val timeStamp = info(3) val sql = "insert into MONITOR_DATA values(AUTO_INCREMENT.NEXTVAL,'" + ip + "','" + mesType + "','" + data + "'," + timeStamp + ")" saveToOracle(connection, sql) }) closeConn(connection) }) val words = rdd.flatMap(_.split(":")) }) ssc.start() ssc.awaitTermination() } //保存数据
6、def saveToOracle(con: Connection, sql: String): Int = { val ps = con.prepareStatement(sql); val res = ps.executeUpdate() ps.close() res } //关闭连接 def closeConn(con: Connection) = { con.close() } //得到连接 def getConnection(): Connection = { val url = "jdbc:oracle:thin:@//192.168.10.100:1521/UCLOUD" Class.forName("oracle.jdbc.driver.OracleDriver").newInstance(); val con = DriverManager.getConnection(url, "scott", "scott"); con } }